Friday, April 3, 2009
No module named servicemanager - building a windows service with py2exe
Trying to build a windows service out of my standalone django application, I was using the various examples available, and kept running into the problem "No module named servicemanager" whenever I tried to run the generated executable. There is almost nothing out there on this, but it occurred to me that perhaps I needed to install/reinstall the Python Win32 Extensions. Turns out, that was it.
Tuesday, March 31, 2009
py2exe can't import packages that should be available (simplejson)
In my py2exe build script, I was specifying a few modules to be imported that for some reason would fail to import. I could import these from the python prompt, but the build script would give the following:
Apparently the problem has to do with that the modules in site-packages stored as zipped eggs would not import. Simply unzipping the simplejson egg contents so that the simplejson directory was in the site-packages directory solved the problem.
running py2exe
*** searching for required modules ***
Traceback (most recent call last):
File "setup.py", line 235, in
console=[ 'runcm.py' ],
File "C:\PYTHON25\LIB\distutils\core.py", line 151, in setup
dist.run_commands()
File "C:\PYTHON25\LIB\distutils\dist.py", line 974, in run_commands
self.run_command(cmd)
File "C:\PYTHON25\LIB\distutils\dist.py", line 994, in run_command
cmd_obj.run()
File "C:\Python25\lib\site-packages\py2exe\build_exe.py", line 243, in run
self._run()
File "C:\Python25\lib\site-packages\py2exe\build_exe.py", line 296, in _run
self.find_needed_modules(mf, required_files, required_modules)
File "C:\Python25\lib\site-packages\py2exe\build_exe.py", line 1297, in find_n
eeded_modules
mf.import_hook(mod)
File "C:\Python25\lib\site-packages\py2exe\mf.py", line 719, in import_hook
return Base.import_hook(self,name,caller,fromlist,level)
File "C:\Python25\lib\site-packages\py2exe\mf.py", line 136, in import_hook
q, tail = self.find_head_package(parent, name)
File "C:\Python25\lib\site-packages\py2exe\mf.py", line 204, in find_head_pack
age
raise ImportError, "No module named " + qname
ImportError: No module named simplejson
Apparently the problem has to do with that the modules in site-packages stored as zipped eggs would not import. Simply unzipping the simplejson egg contents so that the simplejson directory was in the site-packages directory solved the problem.
Thursday, March 12, 2009
'module' object has no attribute 'tostring' - elementtree with py2exe compiled django app
In that Django py2exe compiled app, I am making use of ElementTree. Code that worked properly on my development server was complaining about the ElementTree module I was using not having a tostring method.
Really? Since when does xml.etree.cElementTree (using Python 2.5 here) not have a tostring method?
The answer? When xml.etree.ElementTree isn't present. A number of the cElementTree methods are merely mapped to the ElementTree module, so if the xml.etree.ElementTree isn't included along with xml.etree.cElementTree in the py2exe includes, cElementTree will be missing components.
Really? Since when does xml.etree.cElementTree (using Python 2.5 here) not have a tostring method?
The answer? When xml.etree.ElementTree isn't present. A number of the cElementTree methods are merely mapped to the ElementTree module, so if the xml.etree.ElementTree isn't included along with xml.etree.cElementTree in the py2exe includes, cElementTree will be missing components.
Friday, March 6, 2009
Merge/Combine two pdf pages into a single pdf page (Perl)
I needed to be able to add markup to an existing pdf file. In particular, I have a template and need to add a barcode programmatically. However, I am working mostly in Python and had already written the code to generate my barcode with placement, and wanted to just overlay that onto my existing pdf template.
With the template pdf:

And the barcode pdf:

I was aiming for:

First, I attempted to do this with the pyPdf library.
This works in my samples, but I encountered problems with my application template: my i and E characters were turned invisible. Maybe a font problem?
Here's what I was looking at:

I decided to go with the Perl PDF::API2 library. It properly handled my files and gave me the output I was looking for--with no missing characters.
With the template pdf:

And the barcode pdf:

I was aiming for:

First, I attempted to do this with the pyPdf library.
from pyPdf import PdfFileWriter, PdfFileReader
barcodepdf = PdfFileReader(file("barcode.pdf", "rb"))
templatepdf = PdfFileReader(file("freecar.pdf", "rb"))
output = PdfFileWriter()
barcodePage = barcodepdf.getPage(0)
templatePage = templatepdf.getPage(0)
templatePage.mergePage(barcodePage)
output.addPage(templatePage)
outputStream = file("output.pdf", "wb")
output.write(outputStream)
outputStream.close()
This works in my samples, but I encountered problems with my application template: my i and E characters were turned invisible. Maybe a font problem?
Here's what I was looking at:

I decided to go with the Perl PDF::API2 library. It properly handled my files and gave me the output I was looking for--with no missing characters.
#!/usr/bin/perl
#------------------#
# PROGRAM:
# mergepdfpage.pl
#
# USAGE:
# mergepdfpage.pl in1.pdf in2.pdf out.pdf
#
# DESCRIPTION:
# Combine the first page from
# two input pdf files
# into a single page in a
# new pdf file.
#------------------#
use PDF::API2;
$input1pdf = PDF::API2->open($ARGV[0]);
$input2pdf = PDF::API2->open($ARGV[1]);
$outputpdf = PDF::API2->new;
# Bring in the template page
$page = $outputpdf->importpage($input1pdf,1);
# Overlay the second input page over the first
$page = $outputpdf->importpage
($input2pdf,1, $outputpdf->openpage(1));
#Save the new file
$outputpdf->saveas($ARGV[2]);
Wednesday, March 4, 2009
Django Admin not showing tables under code compiled with py2exe
I have a Django-based project that I am building using py2exe. Unfortunately, the admin piece does not seem to like something here--my development non-py2exed version works fine, but no tables show up in the py2exe version's admin.

So what's the problem? Well, first off, it's rather hard to debug in py2exed Django:

So, after muddling through with thrown exceptions (logging would have been an option as well), I found the culprit.
In django/contrib/admin/__init__.py lives the admin autodiscover() function. The following part of this function doesn't behave as intended:
I'm not familiar with the imp module, but it would seem it as though maybe it requires the python source? Or at least something more pure than the mangled code provided by py2exe.
Since imp.find_module is failing, we can just look to import the admin module for each app:
Now, it's not necessarily going to be convenient to patch the django source, so we can just create our own autodiscover function and call that.
The following goes in my util.py:
And then in urls.py, where autodiscover() was already being called:
Rebuild and we have admin.
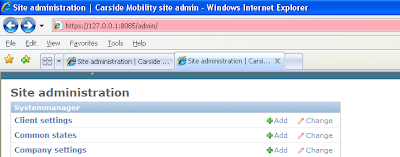

So what's the problem? Well, first off, it's rather hard to debug in py2exed Django:

So, after muddling through with thrown exceptions (logging would have been an option as well), I found the culprit.
In django/contrib/admin/__init__.py lives the admin autodiscover() function. The following part of this function doesn't behave as intended:
# Step 2: use imp.find_module to find the app's admin.py. For some
# reason imp.find_module raises ImportError if the app can't be found
# but doesn't actually try to import the module. So skip this app if
# its admin.py doesn't exist
try:
imp.find_module('admin', app_path)
except ImportError:
continue
I'm not familiar with the imp module, but it would seem it as though maybe it requires the python source? Or at least something more pure than the mangled code provided by py2exe.
Since imp.find_module is failing, we can just look to import the admin module for each app:
try:
imp.find_module('admin', app_path)
except ImportError:
try: #In py2exe compiled code, imp will have failed to find the admin module, so we will guess and try to import the 'app'.admin
__import__(app+'.admin', globals(), locals(), [])
except ImportError:
pass
continue
Now, it's not necessarily going to be convenient to patch the django source, so we can just create our own autodiscover function and call that.
The following goes in my util.py:
from django.contrib.admin import LOADING
LOADING = False
def autodiscover():
"""
Auto-discover INSTALLED_APPS admin.py modules and fail silently when
not present. This forces an import on them to register any admin bits they
may want.
"""
# Bail out if autodiscover didn't finish loading from a previous call so
# that we avoid running autodiscover again when the URLConf is loaded by
# the exception handler to resolve the handler500 view. This prevents an
# admin.py module with errors from re-registering models and raising a
# spurious AlreadyRegistered exception (see #8245).
global LOADING
if LOADING:
return
LOADING = True
import imp
from django.conf import settings
for app in settings.INSTALLED_APPS:
# For each app, we need to look for an admin.py inside that app's
# package. We can't use os.path here -- recall that modules may be
# imported different ways (think zip files) -- so we need to get
# the app's __path__ and look for admin.py on that path.
# Step 1: find out the app's __path__ Import errors here will (and
# should) bubble up, but a missing __path__ (which is legal, but weird)
# fails silently -- apps that do weird things with __path__ might
# need to roll their own admin registration.
try:
app_path = __import__(app, {}, {}, [app.split('.')[-1]]).__path__
except AttributeError:
continue
# Step 2: use imp.find_module to find the app's admin.py. For some
# reason imp.find_module raises ImportError if the app can't be found
# but doesn't actually try to import the module. So skip this app if
# its admin.py doesn't exist
try:
imp.find_module('admin', app_path)
except ImportError:
try: #In py2exe compiled code, imp will have failed to find the admin module, so we will guess and try to import the 'app'.admin
__import__(app+'.admin', globals(), locals(), [])
except ImportError:
pass
continue
# Step 3: import the app's admin file. If this has errors we want them
# to bubble up.
__import__("%s.admin" % app)
# autodiscover was successful, reset loading flag.
LOADING = False
And then in urls.py, where autodiscover() was already being called:
from django.contrib import admin #Still importing the admin module to map our urls
#admin.autodiscover() #We are going to use our custom autodiscover instead
from util import autodiscover
autodiscover()
Rebuild and we have admin.

Monday, February 23, 2009
HTTPS through CherryPy webserver standalone
In trying to get my standalone CherryPy webserver to serve over https, I can across the following CherryPy documentation: http://www.stderr.org/doc/cherrypy-doc/html/howto/node10.html. It stated:
Not so much. I tried this, and then tried to connect over https. The result?
I believe those lines are for configuration with use of Apache, not the standalone server. To get the standalone server working, I had to set server variables as follows (substitute your own relative key/cert/port values):
Once you have PyOpenSSL installed, all you have to do is add 2 lines in your CherryPy config file, in the server section:
sslKeyFile=/path/to/ssl/key/file
sslCertificateFile=/path/to/ssl/certificate/file
And that's it !
Not so much. I tried this, and then tried to connect over https. The result?
SSL received a record that exceeded the maximum permissible length
I believe those lines are for configuration with use of Apache, not the standalone server. To get the standalone server working, I had to set server variables as follows (substitute your own relative key/cert/port values):
cherrypy.server.socket_port = 443
cherrypy.server.ssl_certificate = 'ssl/server.crt'
cherrypy.server.ssl_private_key = 'ssl/rsa.key'
Wednesday, February 18, 2009
VBA Excel - Formatting a column of numbers to a given precision, stripping out the decimal place, and adding leading zeros to satisfy a minimum length
'Return the number dNumber increased to the power iExponent
Function Pow(ByVal dNumber As Double, ByVal iExponent As Integer) As Double
Pow = 1
Dim iCounter As Integer
For iCounter = 1 To iExponent
Pow = Pow * dNumber
Next iCounter
End Function
'Convert the values in the active column to the given precision, with no decimal place, filled with leading zeros to satisfy a minimum length
Sub ConvertColToTextNoDecimal(ByVal iPrecision As Integer, ByVal iMinimumLength As Integer)
Dim row As Long
Dim col As Long
col = Selection.Column 'We are going to process whatever column is currently selected
Dim val As Variant
For row = 2 To ActiveSheet.UsedRange.Rows.Count 'Assume we are processing from below a header row to the last used row in the selected sheet
val = ActiveSheet.Cells(row, col).Value 'Get the current value
On Error GoTo NextRow
val = CStr(Round(CDbl(val) * Pow(10, iPrecision), 0)) 'Round to the given precision, then shift off the decimal place
While Len(val) < iMinimumLength 'If the value we have isn't long enough:
val = "0" & val 'Prepend a zero
Wend
ActiveSheet.Cells(row, col).FormulaR1C1 = "'" & val 'Mark this value as text, so we don't lose any leading zeros
NextRow:
On Error GoTo 0
Next row
End Sub
Example usage:
'Round to 3 decimal places, remove the decimal point
Sub ConvertColTo3Dec()
ConvertColToTextNoDecimal 3, 0
End
'Round to 2 decimal places, remove the decimal point
Sub ConvertColTo2Dec()
ConvertColToTextNoDecimal 2, 0
End Sub
'Round to 1 decimal place, remove the decimal point
Sub ConvertColTo1Dec()
ConvertColToTextNoDecimal 1, 0
End Sub
'Round to 0 decimal places
Sub ConvertColTo0Dec()
ConvertColToTextNoDecimal 0, 0
End Sub
'No decimal place changes, but force enough leading zeros for 3 digits
Sub ConvertColTo0Filled3Long()
ConvertColToTextNoDecimal 0, 3
End Sub
Friday, February 13, 2009
Django: AttributeError: 'module' object has no attribute 'JSONEncoder'
Running a Django syncdb, I've encountered a problem: AttributeError: 'module' object has no attribute 'JSONEncoder'.
Googling says that the problem is that I have python-json installed, and that I need to have python-simplejson installed too. Except that I already do have that installed. So, when running a syncdb, just move json.py in the Python site-packages directory aside for a moment, and everything should run fine.
$ python ./manage.py syncdb
Traceback (most recent call last):
File "./manage.py", line 11, in ?
execute_manager(settings)
File "/usr/lib/python2.4/site-packages/django/core/management/__init__.py", line 347, in execute_manager
utility.execute()
File "/usr/lib/python2.4/site-packages/django/core/management/__init__.py", line 295, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "/usr/lib/python2.4/site-packages/django/core/management/base.py", line 195, in run_from_argv
self.execute(*args, **options.__dict__)
File "/usr/lib/python2.4/site-packages/django/core/management/base.py", line 222, in execute
output = self.handle(*args, **options)
File "/usr/lib/python2.4/site-packages/django/core/management/base.py", line 351, in handle
return self.handle_noargs(**options)
File "/usr/lib/python2.4/site-packages/django/core/management/commands/syncdb.py", line 149, in handle_noargs
call_command('loaddata', 'initial_data', verbosity=verbosity)
File "/usr/lib/python2.4/site-packages/django/core/management/__init__.py", line 158, in call_command
return klass.execute(*args, **options)
File "/usr/lib/python2.4/site-packages/django/core/management/base.py", line 222, in execute
output = self.handle(*args, **options)
File "/usr/lib/python2.4/site-packages/django/core/management/commands/loaddata.py", line 91, in handle
formats = serializers.get_public_serializer_formats()
File "/usr/lib/python2.4/site-packages/django/core/serializers/__init__.py", line 72, in get_public_serializer_formats
_load_serializers()
File "/usr/lib/python2.4/site-packages/django/core/serializers/__init__.py", line 108, in _load_serializers
register_serializer(format, BUILTIN_SERIALIZERS[format], serializers)
File "/usr/lib/python2.4/site-packages/django/core/serializers/__init__.py", line 50, in register_serializer
module = __import__(serializer_module, {}, {}, [''])
File "/usr/lib/python2.4/site-packages/django/core/serializers/json.py", line 44, in ?
class DjangoJSONEncoder(simplejson.JSONEncoder):
AttributeError: 'module' object has no attribute 'JSONEncoder'
Googling says that the problem is that I have python-json installed, and that I need to have python-simplejson installed too. Except that I already do have that installed. So, when running a syncdb, just move json.py in the Python site-packages directory aside for a moment, and everything should run fine.
sslerror: (8, 'EOF occurred in violation of protocol')
I have a program in the field that performs SOAP calls to a server over HTTPS. The program works fine at most places. However, for one customer, the relevant call gives an error of
sslerror: (8, 'EOF occurred in violation of protocol')
I started by taking a look at the stack trace on this guy:
Googling around for this problem suggests that proxies can result in this problem, which is likely caused by the HTTP header send being terminated prematurely. A few people suggested using a different SSL library (M2Crypto), but my solution makes use of ElementSOAP, and I'd really rather not have to mess with that much of the underlying code. So I took a look at the source of these Python packages:
In HTTPClient.py:
It looks like the header send is blowing up before the body of the SOAP message goes--we're not going to be able to just suppress the exception and take our response from the server.
In ElementSOAP.py:
Well, this is interesting. I'm not an expert on proxies or HTTP headers, but I see that SOAPAction extra header getting sent, and I can envision a proxy stripping out that header before sending it on to it's final destination. Result? Headers in violation of protocol (according to IIS)? Maybe. However, the customer claims there is no proxy.
My next thought? This post suggests changing the defaultHttpsTransport in client.py from
httplib.HTTPConnection to M2Crypto.httpslib.HTTPSConnection. Unfortunately, I'm working on SCO Openserver, so I don't know if I'll be able to build M2Crypto for this to work.
Instead, I tried to investigate the problem further. On the non-functioning machine, I just tried to access the URL I am targeting using curl. The result?
Really? Well, just be be sure this would work at all, I tried it on a machine that didn't have the problem.
Coincidence? Or are we onto something? I find another machine that hasn't been running this program, and try the curl command.
And the program gives sslerror: (8, 'EOF occurred in violation of protocol') on this system.
Maybe SSL isn't built the same on the failing machines?
One more time, but on a different machine that is working. This time, the curl command works.
It turns out the failing systems are all running SCO Openserver 5.0.6, while the working systems are running SCO Openserver 5.0.7. Maybe there's a problem with the SSL library installed on 5.0.6? Or the Python installation on those? Or something being used didn't have SSL compiled in, like curl? So maybe the python wrapper calling the SSL library isn't getting what it should be getting out of the library, and then is sending something wrong to the server instead of notifying that something went wrong earlier.
At this point, we've decided we are going to require 5.0.7 for this program, so I'm no longer actively researching a solution.
sslerror: (8, 'EOF occurred in violation of protocol')
I started by taking a look at the stack trace on this guy:
Traceback (most recent call last):
File "/roadware/tire/custom/rt/dcpr", line 257, in main
products = q.getPrices(dealer=opts.dealer, customer_id=opts.customer, document_date=opts.date, pricing_type_id="1", products=opts.products)
File "/roadware/tire/custom/rt/dcpr", line 149, in getPrices
response = self.call(fullaction, gpelem, headerelem)
File "/usr/lib/python2.3/site-packages/elementsoap/ElementSOAP.py", line 209, in call
parser=namespace_parse
File "/usr/lib/python2.3/site-packages/elementsoap/HTTPClient.py", line 147, in do_request
h.endheaders()
File "/opt/K/SCO/python/2.3.4/usr/lib/python2.3/httplib.py", line 712, in endheaders
self._send_output()
File "/opt/K/SCO/python/2.3.4/usr/lib/python2.3/httplib.py", line 597, in _send_output
self.send(msg)
File "/opt/K/SCO/python/2.3.4/usr/lib/python2.3/httplib.py", line 564, in send
self.connect()
File "/opt/K/SCO/python/2.3.4/usr/lib/python2.3/httplib.py", line 985, in connect
ssl = socket.ssl(sock, self.key_file, self.cert_file)
File "/opt/K/SCO/python/2.3.4/usr/lib/python2.3/socket.py", line 73, in ssl
return _realssl(sock, keyfile, certfile)
sslerror: (8, 'EOF occurred in violation of protocol')
Googling around for this problem suggests that proxies can result in this problem, which is likely caused by the HTTP header send being terminated prematurely. A few people suggested using a different SSL library (M2Crypto), but my solution makes use of ElementSOAP, and I'd really rather not have to mess with that much of the underlying code. So I took a look at the source of these Python packages:
In HTTPClient.py:
h.putrequest(method, path)
h.putheader("User-Agent", self.user_agent)
h.putheader("Host", self.host)
h.putheader("Content-Type", content_type)
h.putheader("Content-Length", str(len(body)))
if extra_headers:
for key, value in extra_headers:
h.putheader(key, value)
h.endheaders()
h.send(body)
# fetch the reply
errcode, errmsg, headers = h.getreply()
It looks like the header send is blowing up before the body of the SOAP message goes--we're not going to be able to just suppress the exception and take our response from the server.
In ElementSOAP.py:
# call the server
try:
response = self.__client.do_request(
ET.tostring(envelope),
extra_headers=[("SOAPAction", action)],
parser=namespace_parse
)
except HTTPError, v:
if v[0] == 500:
# might be a SOAP fault
response = namespace_parse(v[3])
Well, this is interesting. I'm not an expert on proxies or HTTP headers, but I see that SOAPAction extra header getting sent, and I can envision a proxy stripping out that header before sending it on to it's final destination. Result? Headers in violation of protocol (according to IIS)? Maybe. However, the customer claims there is no proxy.
My next thought? This post suggests changing the defaultHttpsTransport in client.py from
httplib.HTTPConnection to M2Crypto.httpslib.HTTPSConnection. Unfortunately, I'm working on SCO Openserver, so I don't know if I'll be able to build M2Crypto for this to work.
Instead, I tried to investigate the problem further. On the non-functioning machine, I just tried to access the URL I am targeting using curl. The result?
curl: (1) libcurl was built with SSL disabled, https: not supported!
Really? Well, just be be sure this would work at all, I tried it on a machine that didn't have the problem.
curl: (60) error setting certificate verify locations:
CAfile: /usr/share/curl/curl-ca-bundle.crt
CApath: none
More details here: http://curl.haxx.se/docs/sslcerts.html
curl performs SSL certificate verification by default, using a "bundle"
of Certificate Authority (CA) public keys (CA certs). The default
bundle is named curl-ca-bundle.crt; you can specify an alternate file
using the --cacert option.
If this HTTPS server uses a certificate signed by a CA represented in
the bundle, the certificate verification probably failed due to a
problem with the certificate (it might be expired, or the name might
not match the domain name in the URL).
If you'd like to turn off curl's verification of the certificate, use
the -k (or --insecure) option.
Coincidence? Or are we onto something? I find another machine that hasn't been running this program, and try the curl command.
curl: (1) libcurl was built with SSL disabled, https: not supported!
And the program gives sslerror: (8, 'EOF occurred in violation of protocol') on this system.
Maybe SSL isn't built the same on the failing machines?
One more time, but on a different machine that is working. This time, the curl command works.
It turns out the failing systems are all running SCO Openserver 5.0.6, while the working systems are running SCO Openserver 5.0.7. Maybe there's a problem with the SSL library installed on 5.0.6? Or the Python installation on those? Or something being used didn't have SSL compiled in, like curl? So maybe the python wrapper calling the SSL library isn't getting what it should be getting out of the library, and then is sending something wrong to the server instead of notifying that something went wrong earlier.
At this point, we've decided we are going to require 5.0.7 for this program, so I'm no longer actively researching a solution.
Code Syntax Highlighting on Blogger
Summary:
If you want your code formatted in a Blogger post, just add the following two lines to your template, before the </body> tag.<script src='http://easy-blog-code-syntax-highlighting.googlecode.com/svn/trunk/ebcsh.js' type='text/javascript'/>
<link href='http://www.geocities.com/easyblogcodesyntax/ebcsh.css' rel='stylesheet' type='text/css'/>
Then, just wrap any code in <pre> tags, make sure you add the name="code" attribute, and select the language you are formatting for in the class:
<pre name="code" class="brush: c-sharp;">
function test() : String
{
return 10;
}
</pre>
becomes
function test() : String
{
return 10;
}
Explanation:
The first order of business for this blog was getting code syntax highlighting working. Not too difficult, there's a utility called SyntaxHighlighter that will do this in JavaScript, and instructions here and here on making it work in Blogger. Unfortunately, this still required hosting the Syntax Highlighter files somewhere, and adding some custom code from one of the above posts, or else Blogger adds visible <br/> tags to the line breaks in the code.So, I combined all the relevant JavaScript from the Syntax Highlighter project (built against 2.0.287), added the necessary code to remove the <br/> tags, and put that up on a Google code project here. Then I just linked to that file (ebcsh.js) directly out of the svn trunk.
The css required a little more work, as Firefox refused to load css served from the Google Code's svn trunk. Google served the file with a MIME type of "text/plain", instead of "text/css", so I dialed up 1997 for some swanky free Geocities hosting.
Subscribe to:
Comments (Atom)
